ImpulseDE
Differential expression for time-course data.
DE with an impulse model
We have developed and implemented two differential expression algorithms tailored to time course bulk sequencing data: ImpulseDE and ImpulseDE2. The two methods are based on different statistical frameworks and are appropriate for different situations: ImpulseDE is based on a model-free error model and can be used for any type of time course measurement and may be used for micro array data for example. ImpulseDE2 is tailored to sequencing data (expected counts or counts) and therefore appropriate for RNA-seq, ATAC-seq and ChIP-seq.
We have recently developed LineagePulse, which extends the model of ImpulseDE2 to identify genes that are differentially expressed in an ordered set of single cells. LineagePulse is appropriate for use in singe cell RNA-seq data where cells are ordered according to predicted pseudotime.
ImpulseDE2
ImpulseDE2 can find non-constant expression trajectories which follow a unimodal (impulse) pattern or find trajectories which differ between two conditions (such as case and control). Moreover, ImpulseDE2 can find transiently up or down-regulated genes.
ImpulseDE2 is an R Bioconductor package that can be accessed here. Detailed instructions for usage can be found in the vignette.
Manuscript can be obtained from here.
ImpulseDE
ImpulseDE is an R Bioconductor package for detecting differentially expressed genes whether for a single time course (analysis of differential expression behavior over time) or between two time courses (comparative analysis). It is based on the impulse model introduced by Chechik and Koller in 2009, which captures the impulse-like changes of gene expression typically observed for cells responding to perturbations or environmental changes.
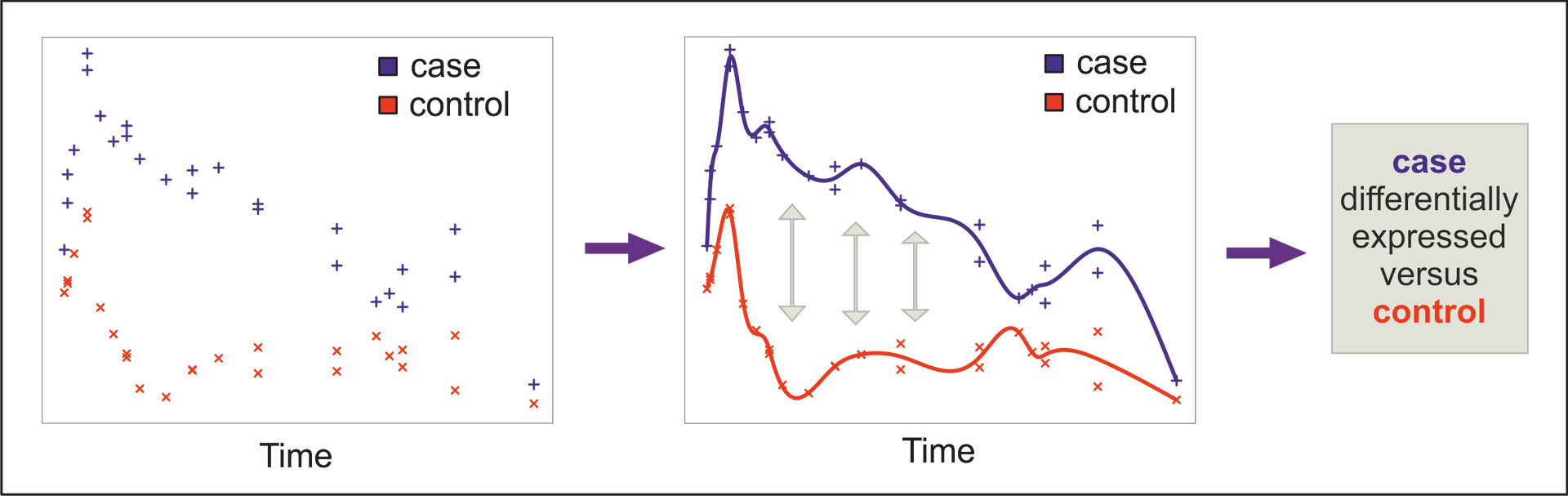
Objective
To test for differential expression in case of a single time course experiment, we evaluate the extent by which the impulse model (representing the alternative hypothesis) fits the expression profile better than a flat line (null hypothesis). In the case of two time courses (case and control) we evaluate the extent to which two models (a separate model for each time course; representing the alternative hypothesis) describe the expression profile better than a single model (null hypothesis; for example, both data sets are generated by the same model (combined)).
Input requirements
- any kind or normalized high throughput expression data set, including microarray and RNA-Seq gene expression data as well as ChiP-seq data
- at least six time points (required for model inference)
Workflow
- The genes are clustered (separately for each time course) using k-means, where k is determined iteratively to optimize the similarity of gene patterns within a cluster.
- The parameters of the impulse model are fit to the mean expression profile of each cluster (minimizing the sum of squared error; SSE) using two different optimization strategies. Since both approaches return local optima, the analysis is repeated 50 times (default) for each strategy using different initializations for the parameters’ values.
- The top three sets of parameters (out of the 100, default) for each cluster are used as starting points to fit the model to each gene separately.
- Random sampling and bootstrapping is used (Storey et al. , 2005) in order to enable the determination of significance levels (evidences to reject the null hypothesis).
- The resulting p-values are FDR-corrected (q-value) to account for multiple testing (Benjamini and Hochberg, 1995).
Features
- The implementation includes the use of multi-threading (running fits to different clusters or different randomized samples in parallel) to further reduce running time
Availability
Manuscript can be obtained here.
Download it on GitHub. ImpulseDE is also available on Bioconductor.